机器人开发中我们会用到触发和别名,在这里经常用到正则表达式。
正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
我们在写用户注册表单时,只允许用户名包含字符、数字、下划线和连接字符(-),并设置用户名的长度,我们就可以使用以下正则表达式来设定。
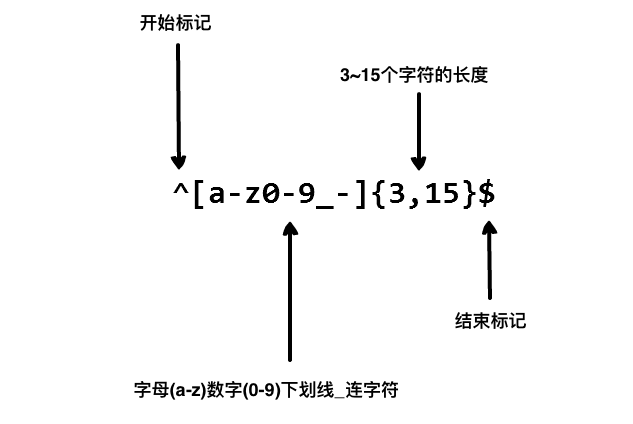
语法
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的文字模式。
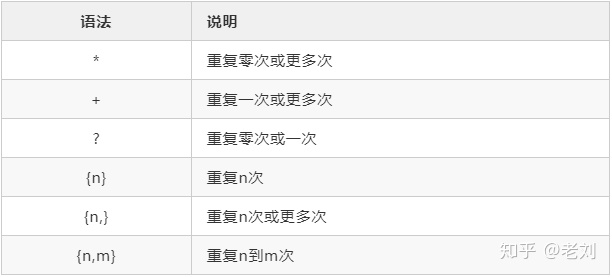
修饰符
修饰符也称为标记(flags),正则表达式的标记用于指定额外的匹配策略。标记不写在正则表达式里,标记位于表达式之外,格式如下:
/pattern/flags
元字符
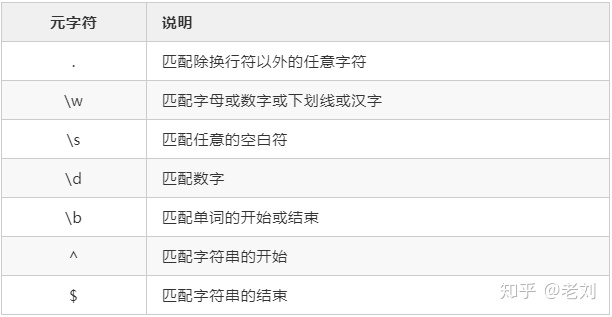
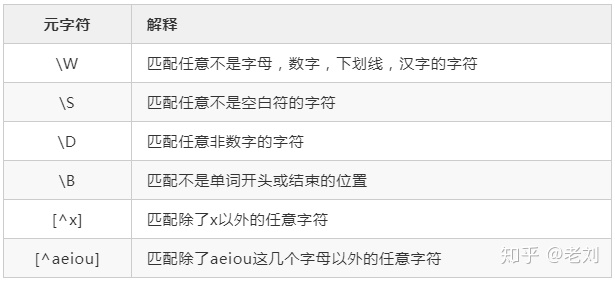
运算符优先级

匹配规则
字符匹配
位置匹配

组

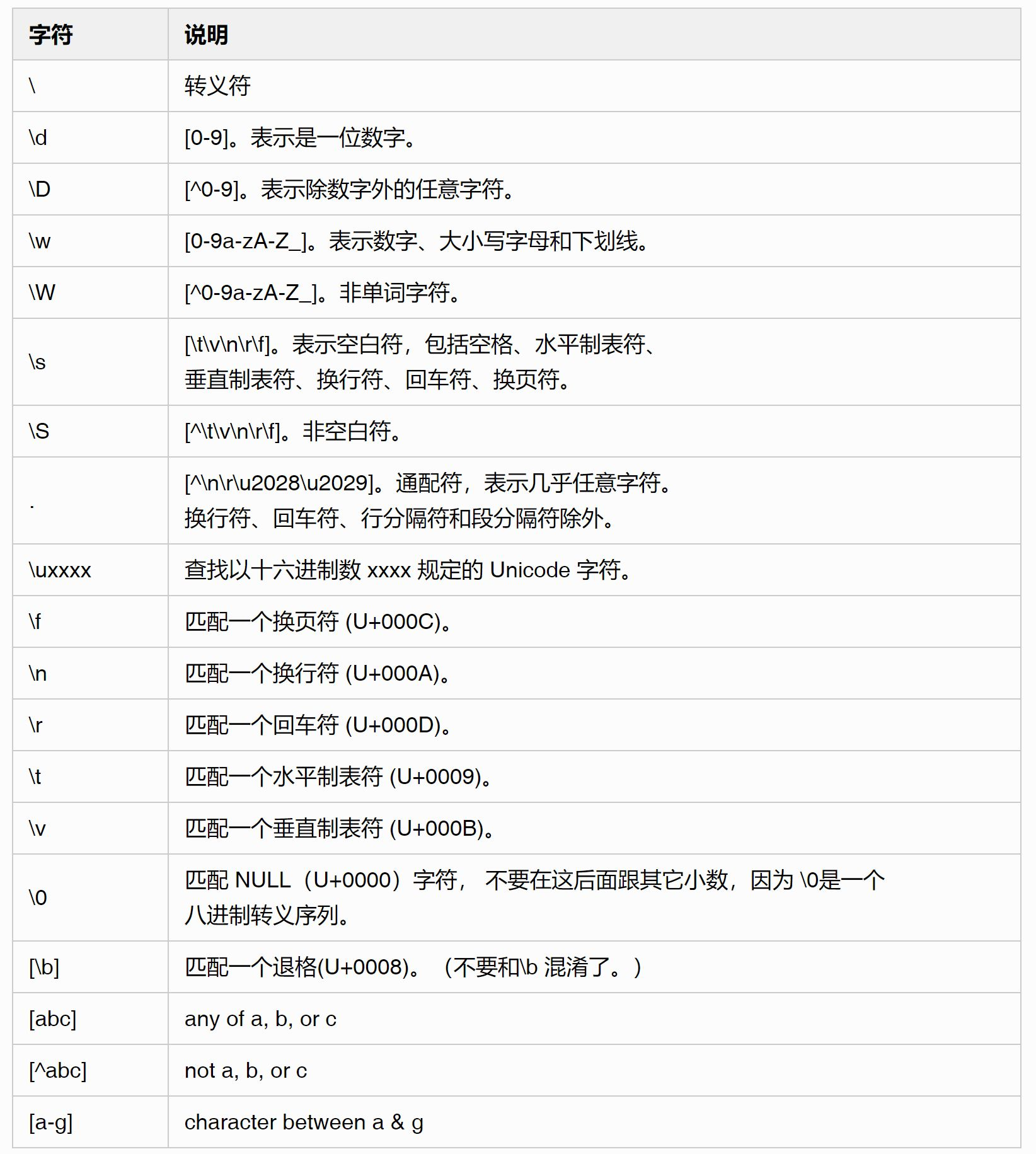
| 字符 | 说明 |
|---|---|
| |
匹配左右任意一个表达式 |
(abc) |
将括弧中的字符做为一个分组 |
\num |
引用捕获的第num个分组 |
?P<name> |
分组取别名为name |
?P=<name> |
引用别名为name的分组 |
提示:这里的分组捕获是mudlet游戏机器人触发的重点,所有分组都会被捕获,在mudlet中会存到变量matches中,其中matches[1]为匹配的触发,matches[2]为捕获的第1个分组,matches[3]为捕获的第2个分组……
mudlet触发中除了序号匹配,也可以自己命名匹配(Named patterns),方式如下:
You can use named patterns - that is, giving your captures names instead of [2], [3], [4] numbers - by adding ?<variablename> to your capture Mudlet 4.11+:
-- before:
(\w+) = matches[2]
-- now:
(?<name>\w+) = matches.name or matches["name"]
(?<weapon>\w+) = matches.weapon or matches["weapon"]This can be particularly handy if you have several patterns in a trigger and the location of matches[n] moves around.
Named capture groups still will be available under their respective number in matches.
You can programatically check if your Mudlet supports this feature with mudlet.supports.namedPatterns.
先行断言

后行断言

量词和分支


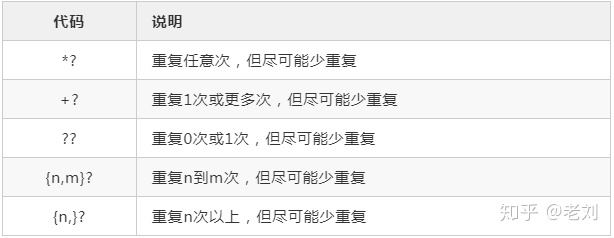
贪婪和非贪婪
贪婪匹配
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符,这匹配方式叫做贪婪匹配。
特性:一次性读入整个字符串进行匹配,每当不匹配就舍弃最右边一个字符,继续匹配,依次匹配和舍弃(这种匹配-舍弃的方式也叫做回溯),直到匹配成功或者把整个字符串舍弃完为止,因此它是一种最大化的数据返回,能多不会少。
懒惰匹配
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能少的字符,这匹配方式叫做懒惰匹配。
特性:从左到右,从字符串的最左边开始匹配,每次试图不读入字符匹配,匹配成功,则完成匹配,否则读入一个字符再匹配,依此循环(读入字符、匹配)直到匹配成功或者把字符串的字符匹配完为止。
懒惰量词是在贪婪量词后面加个“?”
这里还以两种格式提供正则表达式的资料,供你下载和打印以便参考:
相关网站:
- https://regexper.com/
- https://regexlearn.com/
- https://www.lua.org/pil/20.2.html
- http://www.pcre.org/pcre.txt
Mudlet中触发示例
捕获玩家数据
要捕获如下玩家HP和MP数据
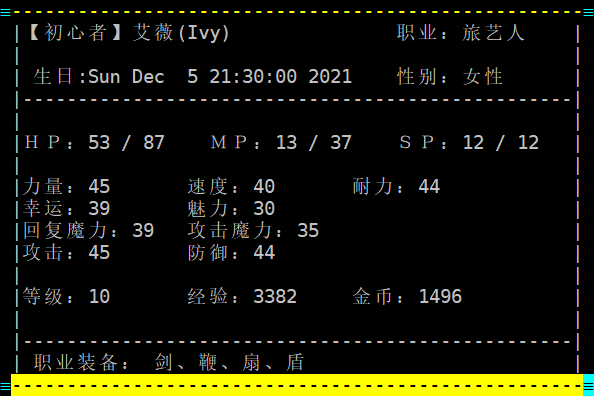
使用如下触发
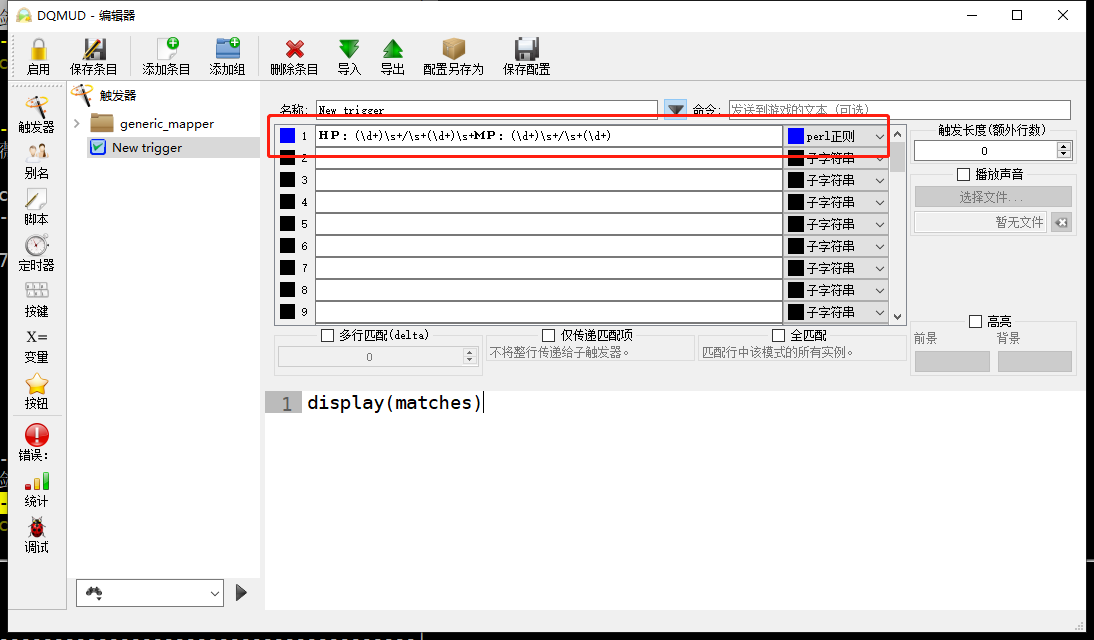
HP:(\d+)\s+/\s+(\d+)\s+MP:(\d+)\s+/\s+(\d+)display(matches)会显示如下:
{ "HP:53 / 87 MP:13 / 37", "53", "87", "13", "37" }matchesp[2]、matchesp[3]、matchesp[4]、matchesp[5]对应53、87、13、37,在脚本区就可以写代码做判断处理了。
结合lua处理匹配
除了直接捕获具体内容外,还可以先范围匹配后通过lua的匹配方法做后期处理,关于Lua的匹配模式请看这里:https://bbs.mud.ren/threads/201
如下示例,通过匹配为方向增加点击功能:
醉仙楼
方圆数百里内提起扬州城醉仙楼可以说是无人不知,无人
不晓。当年苏学士云游到此,对醉仙楼的花雕酒赞不绝口,欣
然为其题匾,流下一段传遍海内的佳话,从此醉仙楼名声大震。
楼下布置简易,顾客多是匆匆的行人,买点包子、鸡腿、米酒
就赶路去了。楼上是雅座。
这里明显的方向有 north、east、west 和 up。
「消息灵通」店小二(xiao er)触发配置如下:

-- display(matches[2])
for exit in string.gmatch(matches[2], "%a+") do
selectString(exit, 1)
setUnderline(true)
setLink([[send("]] .. exit .. [[")]], "移动到" .. exit)
resetFormat()
end这里matches[2]直接匹配的是north、east、west 和 up,但通过string.gmatch(matches[2], "%a+")函数处理匹配返回,在这里%a+相当于[A-Z|a-z]+,结果返回一个方向数组。